Introduction
Auditory-perceptual voice analysis reliably quantifies overall voice quality both in clinical practice and in research settings. Perceptual evaluation is rapid, noninvasive, readily performed, and does not require specialized equipment. Such evaluation is often used to assess the hoarseness of new patients or those undergoing follow-up. The grade, roughness, breathiness, asthenia, and strain (GRBAS) scale is widely used for perceptual evaluation of voice quality (Hirano M. Psycho-acoustic evaluation of voice. Disorders of Human Communication, 5, Clinical Examination of Voice. New York, NY: Springer-Verlag; 1981:81–84). We previously suggested that artificial intelligence (AI) could objectively and effectively classify pathological voice data using this scale (J Voice [published online ahead of print March 13, 2020]. doi:10.1016/j.jvoice.2020.02.009). The deep-learning architecture for voice quality classification is based on TensorFlow, a software library developed and released by Google for use in deep learning. Perceptual ratings are subjective since their accuracy depends on the skill, expertise, and psychophysical status of the evaluator (J Speech Hear Res. 1990;33:103–115), as well as the evaluation time, thus biasing the results. AI eliminates these issues and enables objective assessment.
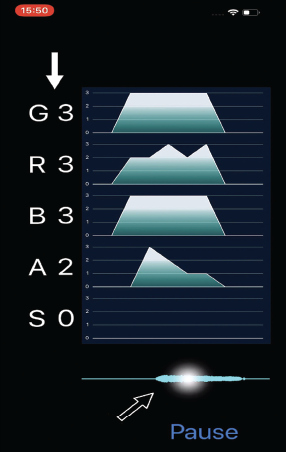
Fig. 1. iPhone application named “GRBASZero.” White arrow: Displayed five voice evaluations in real-time. Black arrow: Tap on the waveform for checking the assessments.
The purpose of this research is to facilitate the use of a deep-learning architecture with the GRBAS scale in clinical practice. To this end, we created an iPhone application named “GRBASZero” to evaluate the voice easily in real time. The deep-learning architecture was prepared with the aid of Create ML and ported to the iPhone using Core ML. Apple provides Create ML and Core ML for the creation of iPhone applications via machine-learning. We initially explored whether Create ML was still the most appropriate software in the present research context.
Method
The subjective assessments of voice quality used the GRBAS scale, which grades voice pathology on a four-point scale (0 = normal to 3 = severe). We constructed a dataset containing 1,377 samples of the sustained vowel /a/ recorded during acoustic analysis of patients’ voices to create a simple machine-learning model that assesses slight temporal changes in voice quality in real time. Voice disorders are caused by vocal-cord polyps, nodules, cysts, atrophy, paralysis, and cancer, as well as by laryngitis. Voices were recorded in a soundproof room as 16-bit/48-kHz WAV files. Three experts rated each sample using the GRBAS scale, and median values were calculated.
We used Create ML to devise and train a machine-learning model using the labeled sounds. MLSoundClassifier was used to classify the voice data. The training dataset was sorted into four classes labeled G0, G1, G2, and G3 using the G data. Similar datasets were created for R, B, A, and S. The training voices ranged in duration from 0.998–8.742 s. During preprocessing, the data were resampled at 16,000 samples/s for 0.975 seconds and divided into several overlapping windows on which Hamming windows were then overlaid and power spectra were calculated via fast Fourier transforms from 125–7500 Hz. The data were filtered using a Mel Frequency Filter Bank, and natural logarithms were calculated. The pre-trained convolutional neural network Google VGGish was then used for feature extraction (https://research.google/pubs/pub45611/). VGGish features 17 convolution/activation layers. The top three layers were removed and replaced with a custom neural network based on the input data. After training, the model was saved as a trained Core ML file, and SoundAnalysis was then used to analyze and classify streamed or file-based voices.
The trained Core ML model was integrated into an iPhone application for voice evaluation in real time (Fig. 1). The application contains trained datasets for G, R, B, A, and S, displays these five voice evaluations in real time, and retains the assessments for later viewing. The system evaluates only sounds above a certain pressure; silence is ignored. Our “GRBASZero” application is available at no cost in the Apple Store.
The purpose of this research is to facilitate the use of a deep-learning architecture with the GRBAS scale in clinical practice.
Results
During training, Create ML randomly splits data into training and validation sets. The model learns iteratively from the training set, and during each iteration it uses the validation set to check its accuracy. We averaged the training and validation scores of five training sessions; the training datasets were randomly chosen and differed for each session. The metrics for the G scale showed high accuracy for the training data (0.806 SD 0.013). The model also had relatively high accuracy for the R scale (0.812 SD 0.008). Among the five categories, accuracy was lowest for the B scale (0.722 SD 0.016) and highest for the S scale (0.914 SD 0.005). The model had acceptable accuracy for the A scale (0.777 SD 0.010). The application was easy to use, requiring only an iPhone. Each score was displayed for 0.975 s. Although phonations of less than 0.975 s were difficult to evaluate correctly, the evaluations were stable when phonation was stable. However, any noise in the examination room destabilized assessment.